Inside Voice
Teaching LLMs to think before they speak by simulating an internal voice
Role: Conception, Programming and Prototyping
Duration: 3 weeks (2024)
Duration: 3 weeks (2024)
Context
In early 2024, "think step by step" prompting was well established—it reliably improved LLM reasoning on complex tasks. But the field hadn't yet converged on why it worked, or how far the principle could be pushed. Extended reasoning architectures like OpenAI's O1 and Anthropic's extended thinking were still months away.
This project explored a hypothesis: that step-by-step prompting works not because it structures output, but because it changes what the model retrieves. If true, the visible reasoning chain is a side effect. The real intervention happens earlier—in how the model queries its own latent space before committing to a response.

The journey from intuition to understanding: like sunlight breaking through layers of thought
The Gap
Ask someone "Who do you trust most?" and the answer comes instantly—a name, a face, a feeling. Now ask them why. There's a pause. They shift from retrieval to reconstruction: interrogating their own intuition, surfacing evidence, sometimes revising the answer entirely.
LLMs exhibit the same gap. They produce confident responses from learned patterns—but when prompted to examine their own reasoning, they access knowledge that wasn't present in the initial output. The latent space holds more than any single forward pass activates.
What if we could design for that gap deliberately—structuring not the output, but the retrieval process itself?
Implementation
The system inserts a multi-stage internal dialogue between user query and model response. Each stage targets a distinct reasoning mode:
- Initial activation — surface the immediate trained response
- Analytical examination — identify assumptions embedded in that response
- Counterevidence retrieval — query for knowledge that complicates or contradicts
- Synthesis — reconcile tensions before generating output
The dialogue operates as a private reasoning layer—the user never sees it. The diagram below shows this applied to a decision-making query, where the system moves from an initial intuition ("seems promising") through problem definition, context analysis, and assumption testing before producing a structured response:

The implementation itself is lightweight—a prompt wrapper that orchestrates the stages and accumulates context across each pass:
Results
I tested the system across ethical dilemmas, ambiguous scenarios, and multi-perspective reasoning tasks, comparing baseline prompting, internal dialogue, and dialogue with augmented retrieval stages.
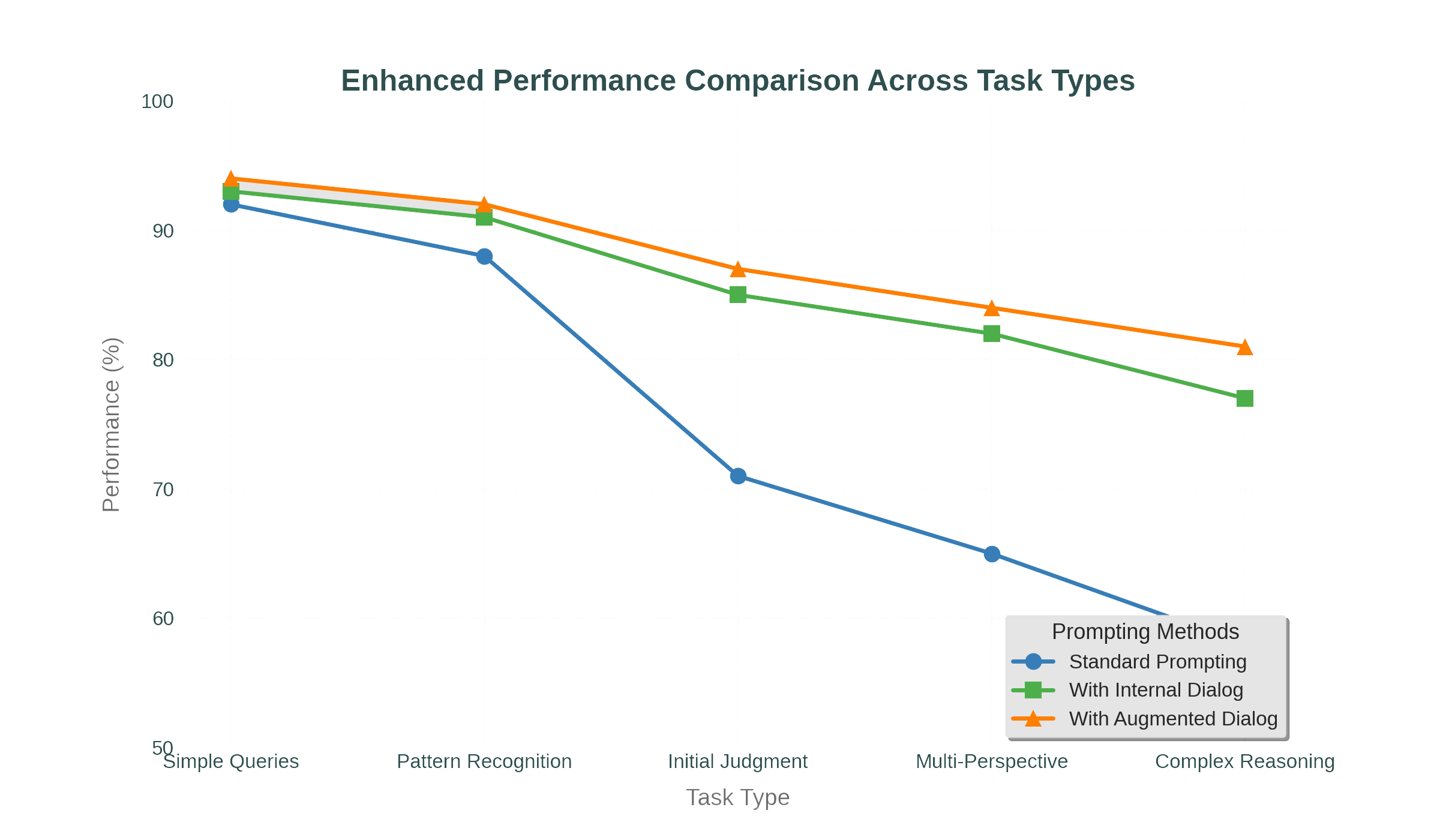
The effect was negligible on simple queries—the model didn't need additional activation. But as task complexity increased, the gap widened. On complex reasoning tasks, the augmented approach outperformed baseline by roughly 20 percentage points.
Three patterns emerged consistently:
• Reduced overconfidence. Responses more frequently acknowledged uncertainty, edge cases, and conditions under which the answer might differ.
• Broader activation. The model drew on more varied evidence, including counterarguments absent from baseline responses.
• Self-correction. In some cases, the model reversed its initial position during internal dialogue—catching flaws in its own reasoning before producing output.
What Came After
Later in 2024, analogous architectures reached production: OpenAI's O1 introduced extended reasoning chains with internal deliberation; Anthropic's extended thinking created a private reasoning space before response generation; their think tool added structured reflection during multi-step tasks.
The convergence validated the core premise of this work: explicit reasoning space activates capabilities that direct prompting does not.
Where This Led
The approach informed subsequent work at Atlassian, extending the core ideas into production contexts I can't detail here. What stayed with me from this project wasn't the performance gains—though those were encouraging. It was the observation that models seem to have more than they use. The latent space holds knowledge, counterarguments, uncertainty that standard prompting never surfaces. Internal dialogue was one way to reach it. There are probably others.